Poradniki
·
12 min czytania
·
14 maja 2026
Jak zrozumieć bias i variance w Machine Learning - przewodnik

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Bias i variance to podstawy machine learning. Andrew Ng, autor kursu CS229 na Stanfordzie, wprost przyznaje: miał doktorantów, którzy po kilku latach pracy w branży wracali i mówili "dopiero teraz naprawdę rozumiem bias i variance". To nie jest wiedza, którą "odhaczasz" - to narzędzie, które doskonalisz przy każdym projekcie.
Ten przewodnik pomoże Ci przeskoczyć pierwsze kilka lat nauki. Zamiast uczyć się na błędach (drogie w czasie i frustracji), dostaniesz mapę terenu. Nie będzie to wykład akademicki - raczej rozmowa o tym, jak te koncepty działają w praktyce i dlaczego ich zrozumienie oszczędza miesiące pracy.
Ten przewodnik zakłada, że:
Jeśli dopiero zaczynasz przygodę z AI, ten przewodnik po kompetencjach AI da Ci lepszy punkt startowy.
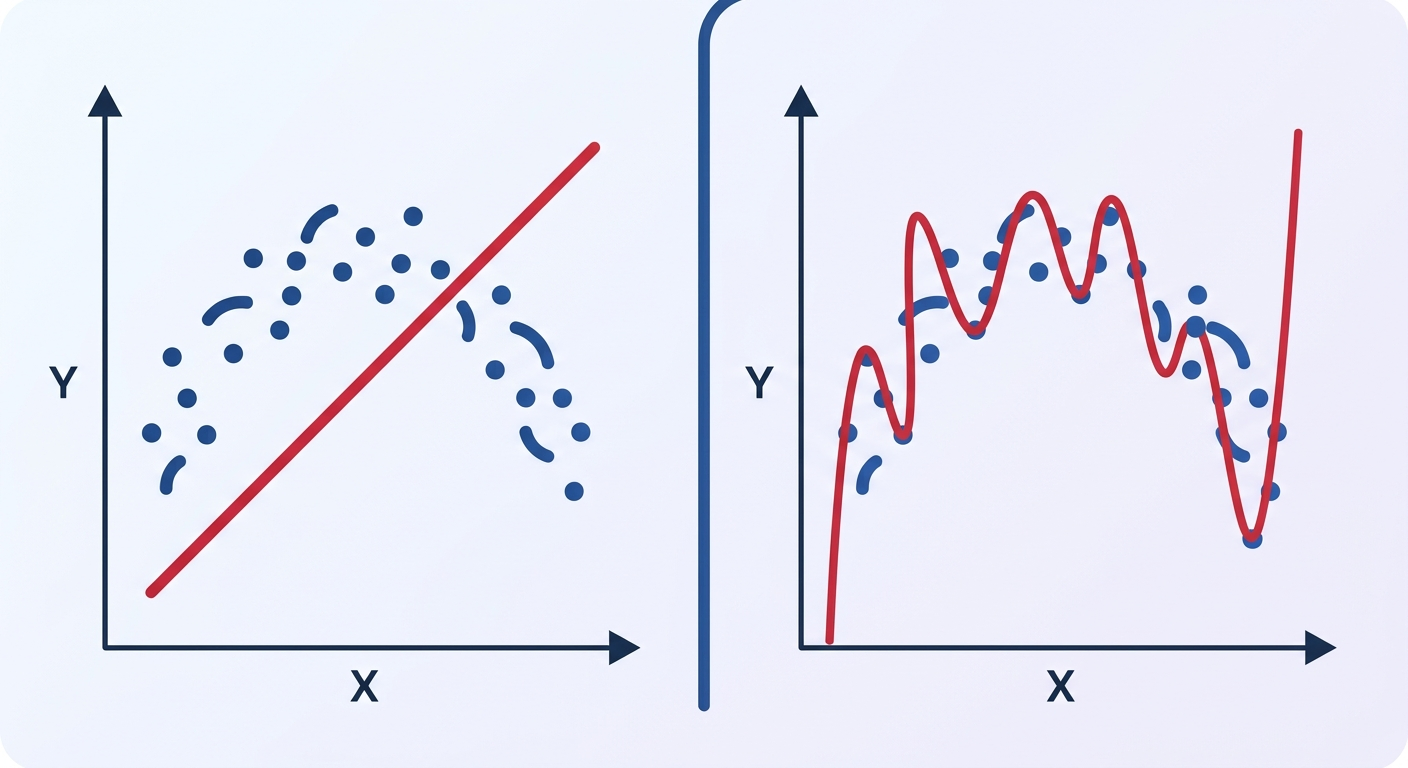
Bias to systematyczny błąd modelu. Mówiąc prościej: Twój model jest za prosty, żeby uchwycić prawdziwe wzorce w danych.
Przykład z życia: masz dane o cenach mieszkań (metraż, lokalizacja, rok budowy) i próbujesz przewidzieć cenę. Jeśli użyjesz prostej regresji liniowej, która zakłada że cena rośnie liniowo z metrem kwadratowym - masz problem. W rzeczywistości zależność nie jest liniowa. Mieszkania w centrum są nieproporcjonalnie droższe, a po przekroczeniu 150m² cena za metr spada. Twój prosty model nigdy tego nie złapie - ma wysoki bias.
Objawy wysokiego bias:
Konkretne kroki:
Kluczowa obserwacja: jeśli Twój model ma 85% accuracy na zbiorze treningowym i 82% na testowym - problem nie jest w overfittingu. Problem jest w tym, że model nie potrafi nawet nauczyć się danych, które widzi. To bias.
Variance to wrażliwość modelu na losowe fluktuacje w danych treningowych. Model z wysokim variance "zapamiętuje" dane zamiast uczyć się wzorców.
Ten sam przykład z mieszkaniami: teraz używasz sieci neuronowej z 10 warstwami ukrytymi na zbiorze 500 mieszkań. Model osiąga 99% accuracy na danych treningowych - idealnie! Ale na nowych mieszkaniach: 65%. Model nauczył się "na pamięć" konkretnych mieszkań ze zbioru treningowego, łącznie z ich przypadkowymi cechami. Może jedno mieszkanie było tanie, bo sprzedawał je rozwodnik w pośpiechu - ale model tego nie wie, tylko "zapamiętał" że mieszkanie o tych parametrach = tania cena.
Objawy wysokiego variance:
Konkretne kroki:
Nie musisz zgadywać. Oto konkretny przepływ decyzyjny:
Przykład z liczbami (klasyfikacja obrazów):
Bias i variance są ze sobą powiązane: zmniejszając jedno, zwykle zwiększasz drugie.
Prosty model (regresja liniowa) → wysoki bias, niski variance. Skomplikowany model (głęboka sieć neuronowa) → niski bias, wysoki variance.
Twoja praca jako osoby budującej model: znaleźć sweet spot - punkt, w którym suma bias + variance jest najmniejsza. To nie jest matematyka, to rzemiosło. Uczysz się tego przez praktykę.
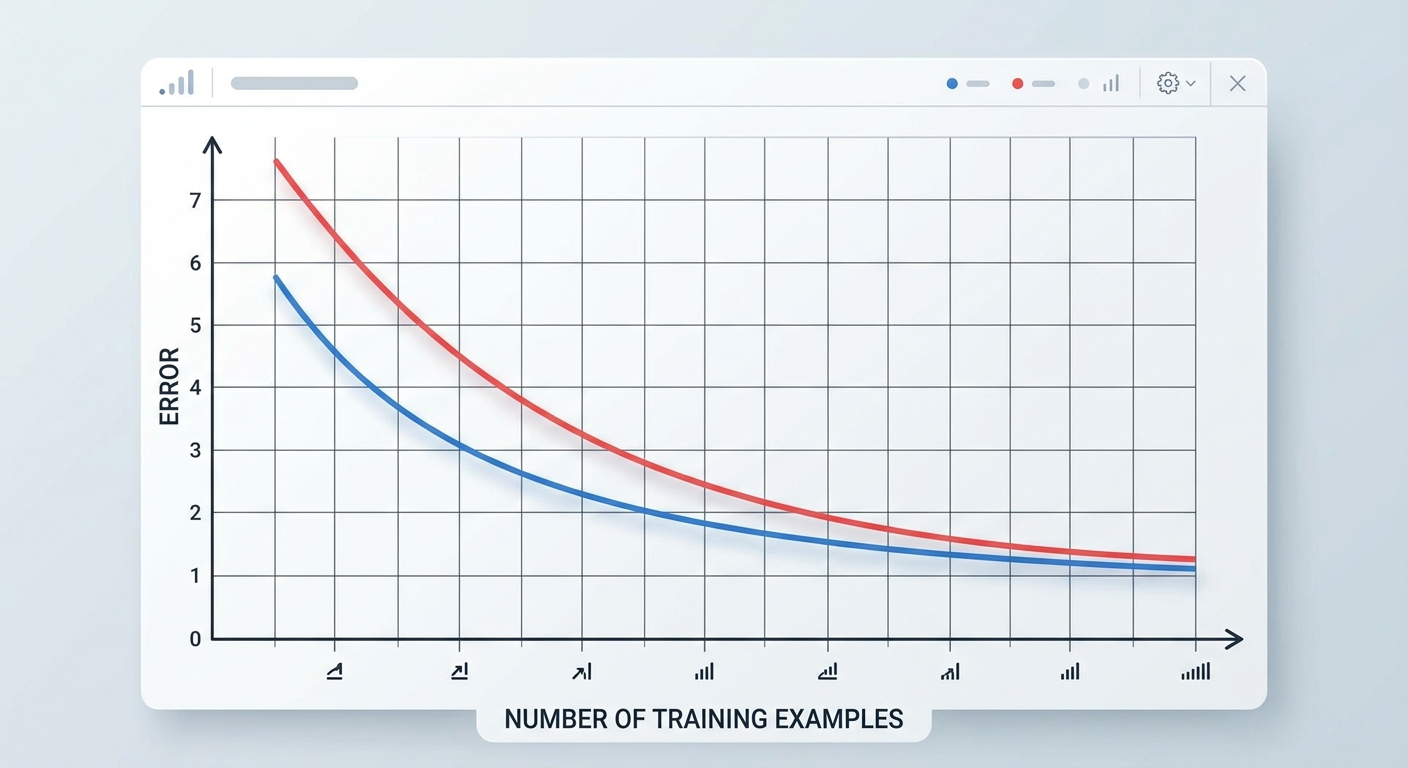
Podział train/test to podstawa. Ale co jeśli miałeś szczęście i Twój zbiór testowy był "łatwy"? Albo pech i był nietypowo trudny? Cross-validation rozwiązuje ten problem.
Zasada: dzielisz dane na K części (najczęściej 5 lub 10). Trenujesz model K razy, za każdym razem używając innej części jako zbioru testowego, a reszty jako treningowego. Na koniec uśredniasz wyniki.
Bonus: dostaniesz też odchylenie standardowe - jeśli wyniki wahają się od 70% do 95%, model jest niestabilny (wysoki variance). Jeśli wszystkie są w okolicy 88% ±2% - model jest solidny.
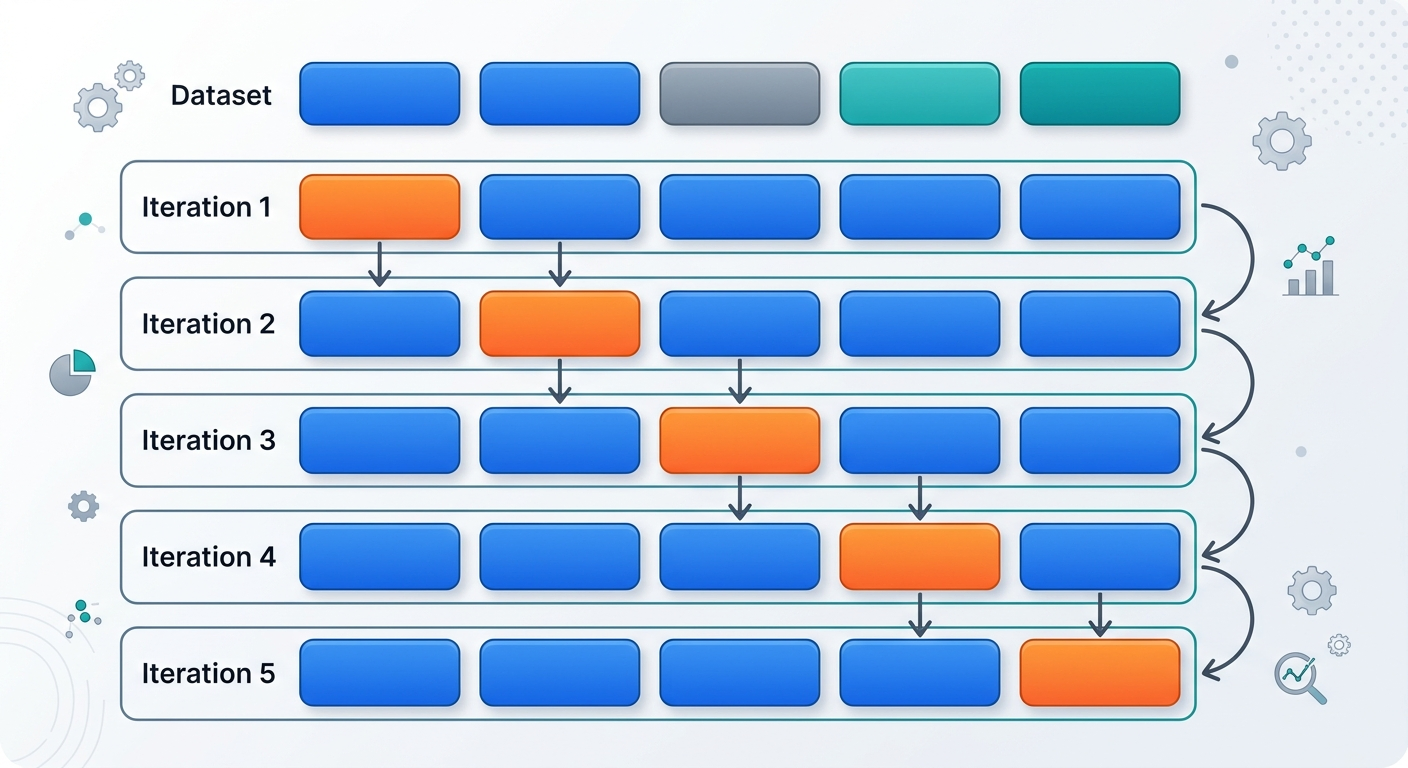
Podstawowy błąd początkujących: dzielą dane na train/test i... trenują model wielokrotnie, za każdym razem sprawdzając wynik na tym samym zbiorze testowym. Potem wybierają najlepszy wariant i wdrażają. Problem? Właśnie "wytrenowali" się na zbiorze testowym. Wyniki będą zawyżone.
Przykład: masz 10 000 zdjęć kotów i psów do klasyfikacji.
Dlaczego to działa? Bo zbiór testowy pozostaje "czysty" - nie miał wpływu na Twoje decyzje o architekturze modelu. To jedyna uczciwa miara tego, jak model poradzi sobie w produkcji.
Zasada praktyczna:
Scenariusz 1: Błąd treningowy 20%, błąd walidacyjny 22%
Diagnoza: wysoki bias. Model za prosty.
Akcja:
Scenariusz 2: Błąd treningowy 2%, błąd walidacyjny 18%
Diagnoza: wysoki variance. Overfitting.
Akcja:
Scenariusz 3: Błąd treningowy 5%, błąd walidacyjny 12%
Diagnoza: lekki overfitting, ale model jest w okolicy sweet spot.
Akcja:
Prawdziwe pytanie: kiedy model jest "wystarczająco dobry"? Nie ma uniwersalnej odpowiedzi. Zależy od problemu:
Ustal próg akceptowalności PRZED rozpoczęciem projektu. Inaczej będziesz optymalizować w nieskończoność.
Współczesne modele (GPT-5, Claude Opus 4.7, Gemini 3.1 Pro) mają miliardy parametrów. Wydawałoby się, że bias/variance to problem z przeszłości. Nic bardziej mylnego.
Te modele są pre-trenowane na ogromnych zbiorach danych. Ale kiedy fine-tunujesz je do swojego zadania (np. klasyfikacja dokumentów prawnych Twojej firmy), znowu wracasz do fundamentów. Masz mały zbiór danych (może 1000 przykładów), duży model - klasyczny setup na overfitting.
Nawet jeśli nie fine-tunujesz, tylko używasz promptów - zrozumienie bias/variance pomaga w debugowaniu. Model konsekwentnie źle klasyfikuje pewien typ dokumentów? To może być bias (prompt za ogólny). Model świetnie działa na Twoich przykładach, ale fatalnie u klienta? Variance (prompt "zapamiętał" Twoje specyficzne przypadki).
Jeśli chcesz głębiej zrozumieć jak pisać prompty do ChatGPT żeby działały, znajomość tych konceptów to fundament.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Bias i variance to nie teoria akademicka. To narzędzia diagnostyczne, które mówią Ci co naprawić w modelu. Wysoki bias? Model za prosty. Wysoki variance? Model się przeuczył. Trade-off między nimi? Normalne - Twoja praca to znaleźć balans.
Cross-validation i poprawny podział danych (train/val/test) chronią Cię przed oszukiwaniem samego siebie. Jeśli testujesz model wielokrotnie na tym samym zbiorze testowym - już się na nim "wytrenowałeś". Wyniki będą zawyżone.
Najważniejsze: te koncepty nie znikną. Nawet w erze GPT-5 i Claude Opus 4.7, kiedy fine-tunujesz model lub debugujesz prompty - wracasz do tych samych fundamentów. Zrozumienie ich teraz oszczędzi Ci miesięcy frustracji później.
Jeśli pracujesz nad modelem teraz: otwórz swoje metryki. Zapisz błąd treningowy i walidacyjny. Porównaj je. To zajmie 2 minuty i da Ci jasną odpowiedź co naprawić jako pierwsze. Jeśli nie pracujesz nad modelem - zapamiętaj ten przepływ decyzyjny. Przyda się przy pierwszym projekcie.
Teoretycznie tak, ale w praktyce rzadko. Jeśli oba błędy (treningowy i testowy) są wysokie i podobne - to głównie bias. Jeśli błąd treningowy niski, a testowy wysoki - to variance. Model zwykle ma dominujący problem z jednym z nich, nie z oboma równocześnie.
Minimum 100-200 przykładów na fold. Jeśli robisz 5-fold CV, potrzebujesz co najmniej 500-1000 przykładów. Poniżej tego progu wyniki będą niestabilne - zbyt mała próbka w każdym foldzie. Jeśli masz mniej niż 500 przykładów, rozważ leave-one-out CV (każdy przykład jest raz zbiorem testowym) albo po prostu zbierz więcej danych.
Prawie zawsze, ale nie zawsze. Regularyzacja (L1, L2, dropout) "karze" model za zbyt skomplikowane rozwiązania, co zwykle pomaga. Ale jeśli przesadzisz (zbyt silna regularyzacja), wprowadzisz bias - model stanie się za prosty. To znowu trade-off. Zacznij od lekkiej regularyzacji i zwiększaj stopniowo, monitorując błąd walidacyjny.
Jeśli masz dość danych (>10 000 przykładów) - tak. Jeśli masz mało (<5000) - cross-validation jest lepsza, bo nie "marnujesz" 20% danych na zbiór testowy. W przypadku średnich zbiorów (5-10k) możesz użyć hybrydowego podejścia: cross-validation na etapie eksperymentów, potem finalny test na odłożonym zbiorze przed wdrożeniem.
Klasyczny problem: Twoje dane treningowe nie reprezentują rzeczywistości. Może zbierałeś je w kontrolowanych warunkach, a w produkcji dane są "brudniejsze". Albo rozkład klas się zmienił (w treningu 50/50 kotów i psów, w produkcji 90% kotów). Rozwiązanie: zbierz dane z produkcji i przetrenuj model. Albo użyj data augmentation żeby symulować "brudne" dane już na etapie treningu.
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Regresja liniowa dobrze sprawdza się na prostych danych. Ale co zrobić, gdy zależności nie układają się w linię prostą? Poznaj dwa rozszerzenia: regresję lokalnie ważoną i logistyczną.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Chcesz zrozumieć, jak naprawdę działają duże modele językowe? Zbuduj swój własny - krok po kroku, bez magii. Przewodnik dla osób bez doświadczenia w programowaniu.

Regresja liniowa to najprostszy algorytm uczenia maszynowego. Dowiesz się, jak działa gradient descent i jak wytrenować pierwszy model krok po kroku.

Syntetyczne dane to sztucznie wygenerowane informacje, które uczą modele AI bez udostępniania prawdziwych danych. Poznaj 3 praktyczne zastosowania i naucz się, jak zacząć.

Uczenie przez wzmacnianie sprawia, że ChatGPT rozumie kontekst, a nie tylko składa słowa. Wyjaśniamy krok po kroku, jak to działa i dlaczego ma znaczenie.
