Poradniki
·
9 min czytania
·
8 maja 2026
Jak tworzyć syntetyczne dane do AI - przewodnik dla początkujących

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Mówią, że AI potrzebuje milionów przykładów, żeby się czegokolwiek nauczyć. I mają rację - ale nikt nie powiedział, że te przykłady muszą być prawdziwe. Syntetyczne dane to sztucznie wygenerowane informacje, które uczą modele AI bez udostępniania rzeczywistych zdjęć, dokumentów czy danych osobowych. To nie obejście problemu - to sposób, żeby trenować AI tam, gdzie prawdziwe dane są drogie, rzadkie albo zbyt wrażliwe.
W tym przewodniku dowiesz się, czym są syntetyczne dane, jak je tworzyć i kiedy warto po nie sięgnąć. Konkretne kroki i przykłady, które możesz wykorzystać od razu.
Syntetyczne dane to informacje wygenerowane sztucznie przez algorytmy, nie zebrane z rzeczywistego świata. Zamiast fotografować tysiące samochodów na ulicy, generujesz je w programie 3D. Zamiast zbierać dokumenty medyczne pacjentów, tworzysz sztuczne opisy przypadków - wyglądają jak prawdziwe, ale nie naruszają prywatności nikogo.
Prawdziwe dane mają trzy podstawowe problemy:
Syntetyczne dane rozwiązują te trzy problemy jednocześnie. Generujesz tyle przykładów, ile potrzebujesz. Kontrolujesz, co się w nich znajduje. I nie naruszasz niczyjej prywatności, bo dane nie dotyczą prawdziwych osób.
Jeśli budujesz system rozpoznający obiekty - samochody, produkty, ludzi - możesz wygenerować tysiące zdjęć bez wychodzenia z domu. Używasz silnika 3D (Blender, Unity, Unreal Engine) i renderujesz sceny z różnych kątów, przy różnym oświetleniu, z różnymi tłami.
Konkretne kroki:
Przykład: firma budująca system autonomicznej jazdy generuje miliony zdjęć ulic, pieszych i znaków drogowych w symulacji - zamiast jeździć samochodem po całym świecie. Taniej, szybciej i bezpieczniej.
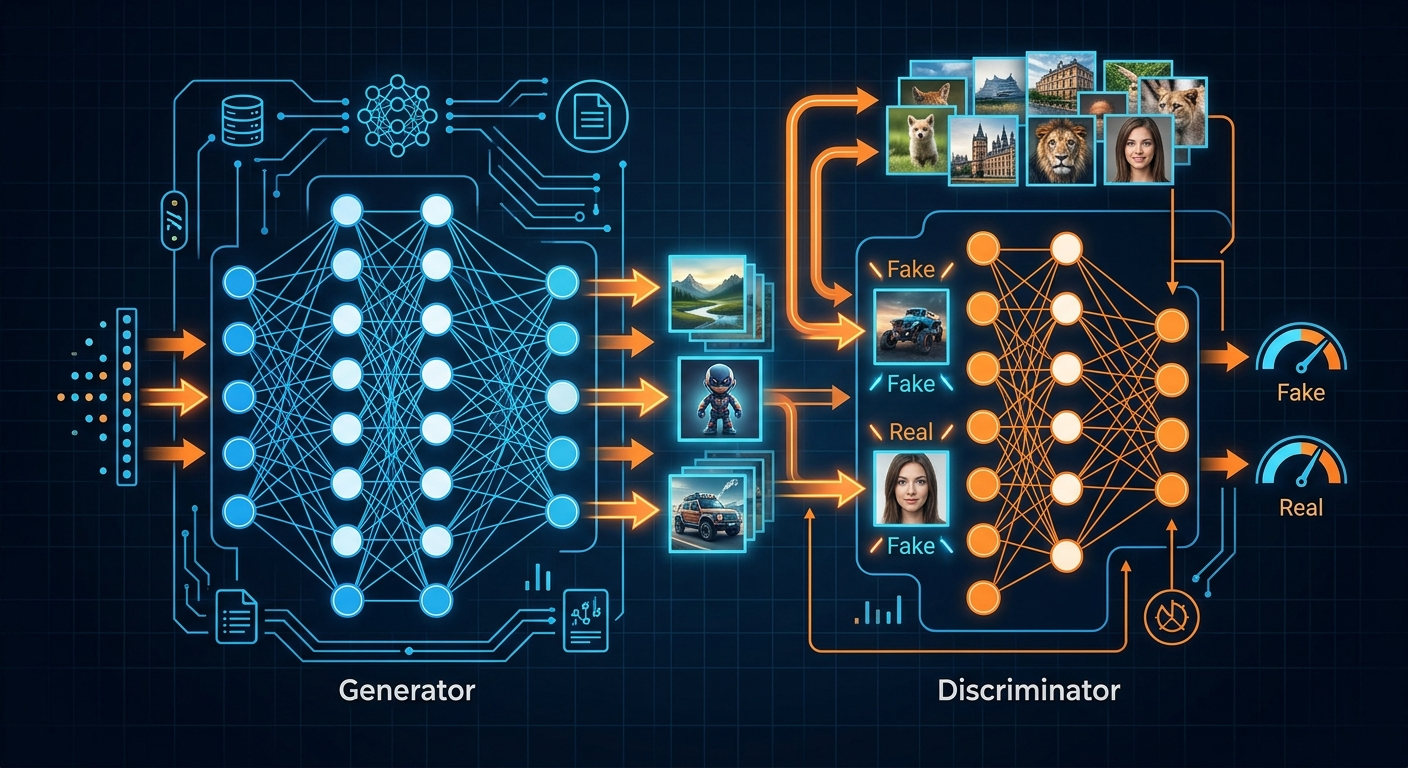
Jeśli masz mały zbiór prawdziwych danych, możesz nauczyć model generatywny, żeby tworzył podobne przykłady. GAN (Generative Adversarial Network) to dwa modele walczące ze sobą: jeden generuje fałszywe obrazy, drugi próbuje je odróżnić od prawdziwych. Z czasem fałszywe stają się nieodróżnialne.
Konkretne kroki:
Przykład: masz 500 zdjęć rzadkiej choroby skóry. Trenujesz GAN, który generuje kolejne 5000 syntetycznych zdjęć - wystarczająco podobnych, żeby model AI nauczył się wzorców, ale nie identycznych z oryginałami.
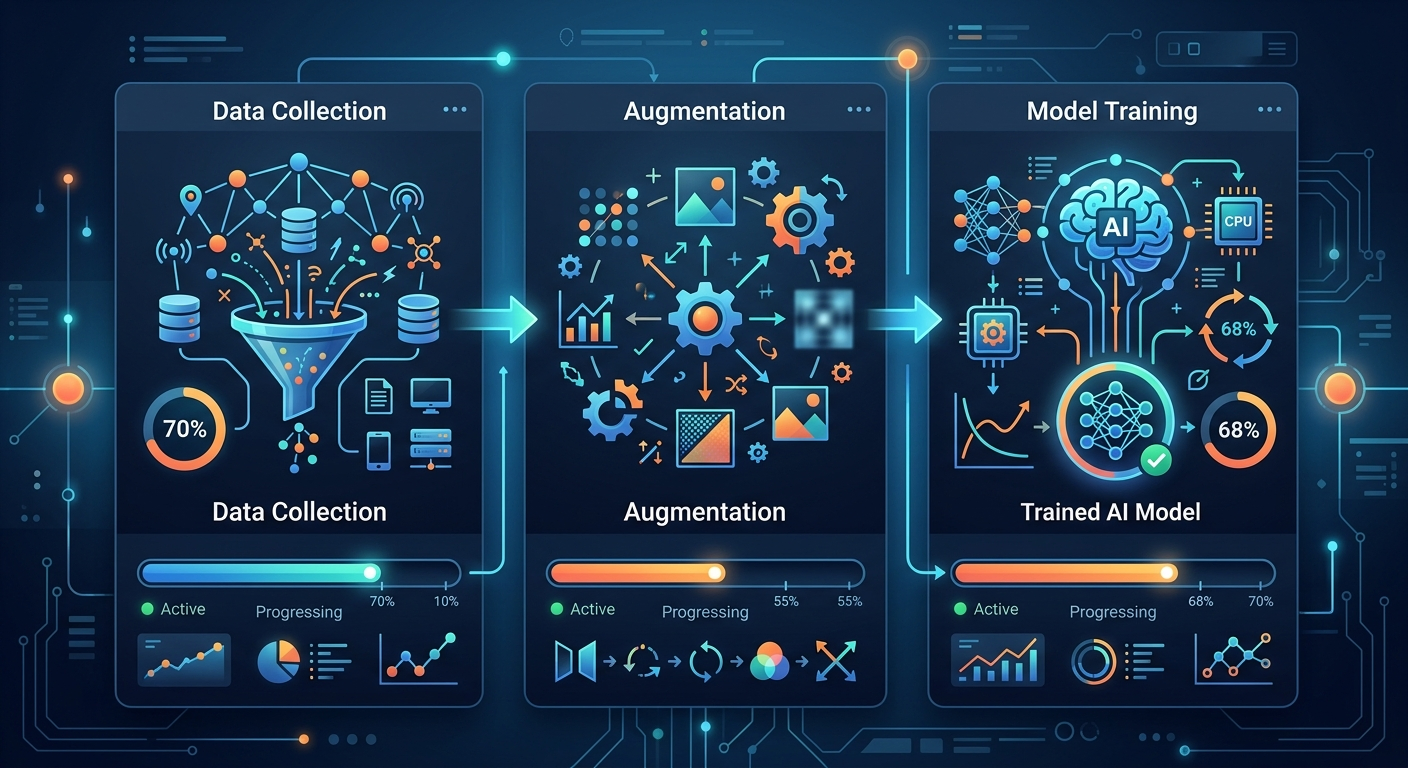
To nie do końca generowanie od zera, ale modyfikacja istniejących danych. Bierzesz prawdziwe zdjęcie i tworzysz jego warianty: obracasz, przycinasz, zmieniasz jasność, dodajesz szum. Każdy wariant to nowy przykład treningowy.
Konkretne kroki:
Przykład: masz 100 zdjęć produktu. Augmentacja daje Ci 1000 zdjęć - wystarczająco, żeby model nauczył się rozpoznawać produkt w różnych warunkach oświetleniowych i kątach.
Jeśli chcesz poznać więcej technik pracy z danymi AI, sprawdź nasz przewodnik po przetwarzaniu danych.
Budujesz system wykrywający defekty w produkcji. Problem? Defekty zdarzają się rzadko - masz 50 przykładów wadliwych produktów i 10 000 prawidłowych. Model uczy się, że wszystko jest OK, bo tak jest w 99% przypadków.
Rozwiązanie: generujesz syntetyczne przykłady defektów. Używasz GAN albo symulacji, żeby stworzyć 5000 zdjęć wadliwych produktów. Teraz model ma wystarczająco dużo przykładów, żeby nauczyć się wzorców.
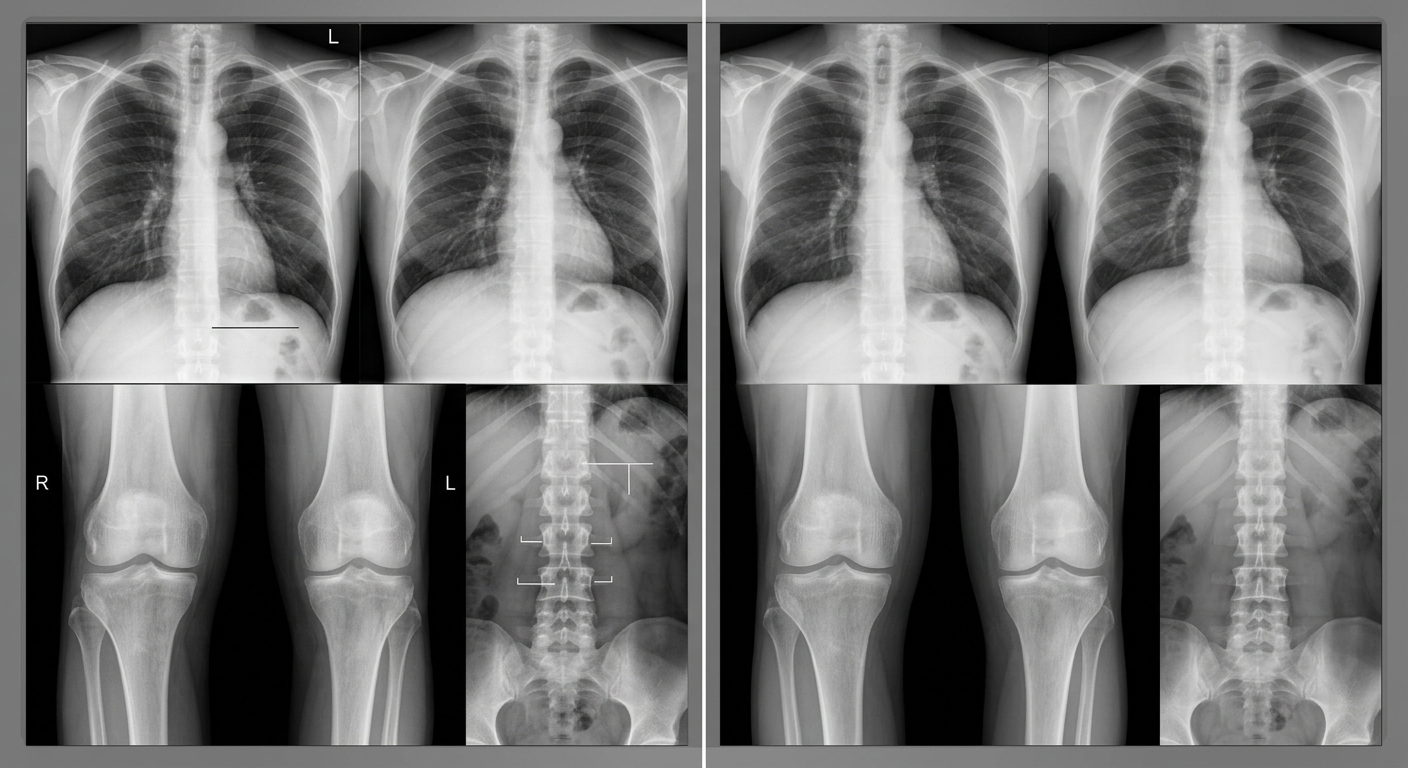
Pracujesz w szpitalu i chcesz nauczyć model rozpoznawać choroby na podstawie zdjęć RTG. Nie możesz udostępnić prawdziwych zdjęć pacjentów - RODO, tajemnica lekarska, zgody.
Rozwiązanie: generujesz syntetyczne zdjęcia RTG, które wyglądają jak prawdziwe, ale nie dotyczą żadnego konkretnego pacjenta. Model uczy się wzorców bez naruszania prywatności.
Budujesz system autonomicznej jazdy. Chcesz sprawdzić, jak zachowa się w śnieżycy, na oblodzonym asfalcie, przy zachodzie słońca - zbieranie takich danych w terenie jest drogie i czasochłonne.
Rozwiązanie: generujesz syntetyczne scenariusze w symulacji. Testujesz model w tysiącach ekstremalnych warunków bez ryzyka wypadku.
Jeśli dopiero zaczynasz przygodę z AI i chcesz zrozumieć, jak trenować modele, zajrzyj do naszego przewodnika po fine-tuningu.
Syntetyczne dane mogą być za bardzo idealne. Jeśli generujesz zdjęcia produktów w symulacji, wszystkie będą miały perfekcyjne oświetlenie, brak szumów, idealną ostrość. Model nauczy się rozpoznawać tylko takie idealne przypadki - a w rzeczywistości zdjęcia są zamazane, niedoświetlone, zrobione pod złym kątem.
Rozwiązanie: dodaj szum, artefakty, niedoskonałości do syntetycznych danych. Symuluj rzeczywiste warunki, nie laboratoryjne.
Jeśli generujesz syntetyczne twarze, ale wszystkie mają podobny wiek, kolor skóry, fryzurę - model nauczy się wąskiego wzorca. W rzeczywistości ludzie są różnorodni.
Rozwiązanie: kontroluj parametry generacji. Upewnij się, że syntetyczne dane pokrywają cały zakres zmienności, który wystąpi w produkcji.
Model wytrenowany tylko na syntetycznych danych może nie działać w rzeczywistości. Syntetyczne dane są przybliżeniem - nie kopią.
Rozwiązanie: zawsze testuj model na prawdziwych danych przed wdrożeniem. Syntetyczne dane uczą, prawdziwe weryfikują.
Zanim rzucisz się w generowanie syntetycznych danych, upewnij się, że:
Jeśli pracujesz z modelami AI i chcesz nauczyć się, jak je wdrażać w produkcji, przeczytaj nasz przewodnik po wdrożeniach AI.
Tak. Syntetyczne dane nie dotyczą prawdziwych osób, więc nie podlegają RODO ani innym regulacjom dotyczącym danych osobowych. Uwaga - jeśli generujesz je na podstawie prawdziwych danych osobowych, musisz mieć zgodę na ich przetwarzanie w procesie treningu modelu generatywnego.
Zależy. W niektórych zadaniach (np. wizja komputerowa, symulacje fizyczne) syntetyczne dane działają równie dobrze. W innych (np. rozpoznawanie emocji, analiza języka naturalnego) prawdziwe dane wciąż wygrywają. Najlepsze wyniki daje połączenie: trenujesz na syntetycznych, doszkalasz na prawdziwych.
Zależy od metody. Augmentacja danych to koszt zerowy (poza czasem procesora). Symulacje 3D wymagają licencji silnika (Unity/Unreal - darmowe do pewnego progu przychodów) i czasu renderowania. Modele generatywne (GAN, Diffusion) wymagają mocy obliczeniowej - od kilkuset złotych (trening w chmurze) do kilku tysięcy (własne GPU). Platformy SaaS typu Gretel.ai działają na subskrypcji - od kilkuset dolarów miesięcznie.
Tak. GPT-5, Claude Opus 4.7 czy Gemini 3.1 Pro świetnie generują syntetyczne dialogi, opisy, dokumenty. Przykład: „wygeneruj 100 przykładów zapytań klientów o zwrot produktu” - model wyprodukuje różnorodne warianty. Koszt? Około $0.50-2 za 1000 przykładów (w zależności od modelu i długości). Jeśli chcesz nauczyć się pisać skuteczne prompty, sprawdź nasz przewodnik po promptach.
Trenujesz dwa modele: jeden na prawdziwych danych, drugi na syntetycznych. Testujesz oba na tym samym zbiorze testowym (prawdziwe dane). Jeśli różnica w wynikach to mniej niż 5-10%, syntetyczne dane są wystarczająco dobre. Jeśli więcej - musisz poprawić jakość generacji (więcej różnorodności, mniej idealności, lepsze parametry).
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Syntetyczne dane to sposób na uczenie modeli AI tam, gdzie prawdziwe dane są drogie, rzadkie albo wrażliwe. Generujesz je w symulacji, przez modele generatywne albo augmentację - w zależności od zadania. Kluczowe zasady: dodawaj niedoskonałości (żeby dane były realistyczne), kontroluj różnorodność (żeby model nie uczył się wąskich wzorców) i zawsze waliduj na prawdziwych danych (żeby sprawdzić, czy działa).
Jeden krok na start: Jeśli masz zbiór zdjęć albo tabel, otwórz bibliotekę Albumentations (dla obrazów) albo SDV (dla tabel) i wygeneruj 10 wariantów jednego przykładu. Zobaczysz, jak działa augmentacja - najprostsza forma syntetycznych danych. To zajmie Ci 15 minut, a zrozumiesz koncept w praktyce.
Na podstawie: Materiały kursu AI Evolution
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Regresja liniowa dobrze sprawdza się na prostych danych. Ale co zrobić, gdy zależności nie układają się w linię prostą? Poznaj dwa rozszerzenia: regresję lokalnie ważoną i logistyczną.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Chcesz zrozumieć, jak naprawdę działają duże modele językowe? Zbuduj swój własny - krok po kroku, bez magii. Przewodnik dla osób bez doświadczenia w programowaniu.

Bias i variance to fundamenty uczenia maszynowego. Zrozumiesz je w 10 minut - ale opanowanie zajmie lata. Zacznij od podstaw, które działają.

Regresja liniowa to najprostszy algorytm uczenia maszynowego. Dowiesz się, jak działa gradient descent i jak wytrenować pierwszy model krok po kroku.

Context Engineering to sposób na lepsze wyniki z AI. Dowiedz się, jak dostarczać modelom właściwy kontekst, by otrzymać dokładne odpowiedzi - bez żargonu i zaawansowanej wiedzy technicznej.
