Poradniki
·
8 min czytania
·
4 czerwca 2026
Jak zrozumieć uczenie przez wzmacnianie w AI - przewodnik

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Otwierasz ChatGPT, zadajesz pytanie i dostajesz odpowiedź, która brzmi... ludzko. Nie jak zlepek słów z Wikipedii, ale jak gdyby ktoś naprawdę zrozumiał, o co Ci chodzi. Skąd AI wie, że ma być pomocne, a nie tylko poprawne gramatycznie?
Odpowiedź: uczenie przez wzmacnianie. To mechanizm, który sprawia, że duże modele językowe (LLM) jak GPT-5, Claude Opus 4.7 czy Gemini 3.1 Pro potrafią dostosować się do tego, czego naprawdę potrzebujesz.
W tym przewodniku rozbijemy temat na czynniki pierwsze. Bez żargonu, bez matematyki - tylko konkretne wyjaśnienie, jak to działa i dlaczego warto to rozumieć.

Zacznijmy od podstaw. Uczenie przez wzmacnianie (ang. reinforcement learning, RL) to sposób trenowania AI, w którym model uczy się przez próby i błędy. Dokładnie jak Ty, gdy uczyłeś się jeździć na rowerze.
Nie czytałeś instrukcji "jak trzymać równowagę". Próbowałeś, przewracałeś się (kara), poprawiałeś, w końcu jechałeś prosto (nagroda). Po setce prób Twój mózg wiedział, co działa.
AI działa podobnie. Masz trzy elementy:
Model generuje odpowiedź. Człowiek (lub inny model) ocenia: pomocna czy nie. Model dostaje punkty za dobre odpowiedzi, traci za złe. Po tysiącach takich iteracji uczy się, co działa.
Klasyczne uczenie maszynowe działa jak egzamin testowy. Pokazujesz modelowi milion przykładów "pytanie → poprawna odpowiedź" i mówisz: zapamiętaj wzorce. Model staje się dobry w rozpoznawaniu tego, co widział.
Problem? Życie nie jest testem wyboru. Gdy pytasz ChatGPT "jak napisać maila do szefa, który się wkurzył", nie ma jednej poprawnej odpowiedzi. Jest milion wariantów - niektóre pomocne, inne katastrofalne.
Uczenie przez wzmacnianie uczy model oceniać jakość, nie tylko poprawność. Dlatego GPT-5 potrafi dostosować ton, długość, styl - został wytrenowany na sygnałach "to było bardziej pomocne niż tamto".
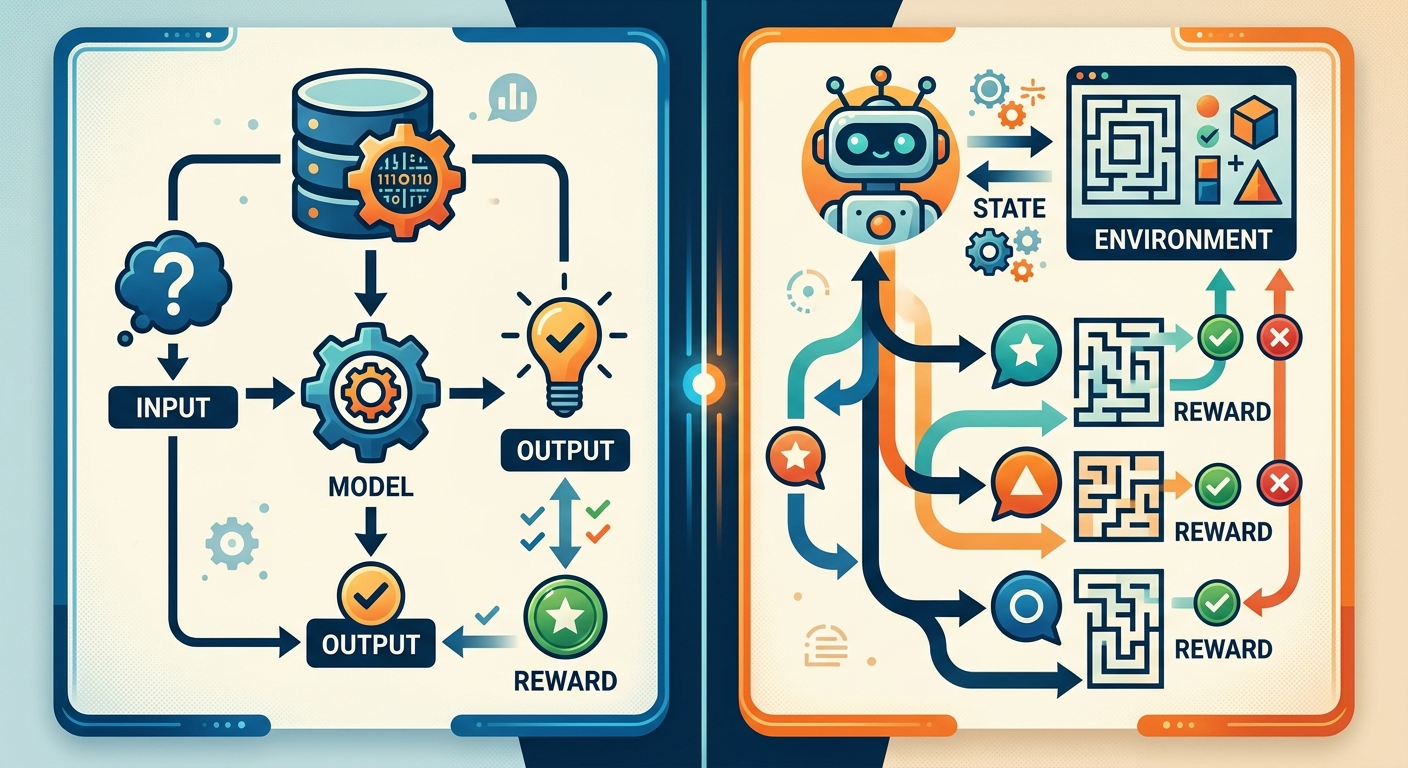
Weźmy konkretny przykład. Trenujesz model, żeby odpowiadał na pytania użytkowników. Oto co się dzieje:
Użytkownik pyta: "Jak nauczyć się Pythona?"
Model (jeszcze niewyuczony) generuje trzy warianty:
Trener (człowiek) przydziela punkty:
Model analizuje: "OK, gdy ktoś pyta 'jak się nauczyć X', ludzie cenią konkretne kroki, nie definicje z podręcznika". Przy następnym pytaniu częściej generuje odpowiedzi w stylu wariantu 2.
Po milionach takich iteracji model "wie" (w cudzysłowie - to statystyka, nie świadomość), że:
Dlatego nowoczesne modele AI potrafią dostosować ton do kontekstu. Zostały wytrenowane na tysiącach sygnałów "taka odpowiedź była lepsza".
W praktyce większość dużych modeli językowych używa wariantu zwanego RLHF (Reinforcement Learning from Human Feedback - uczenie przez wzmacnianie z ludzką informacją zwrotną).
Proces wygląda tak:
Efekt? Claude Opus 4.7 czy GPT-5 potrafią pisać maile, które brzmią profesjonalnie. Gemini 3.1 Pro potrafi wyjaśnić skomplikowany temat prostym językiem. DeepSeek V4-Pro potrafi debugować kod i sugerować poprawki.
Zostały wytrenowane na milionach przykładów "to było pomocne / to nie było".
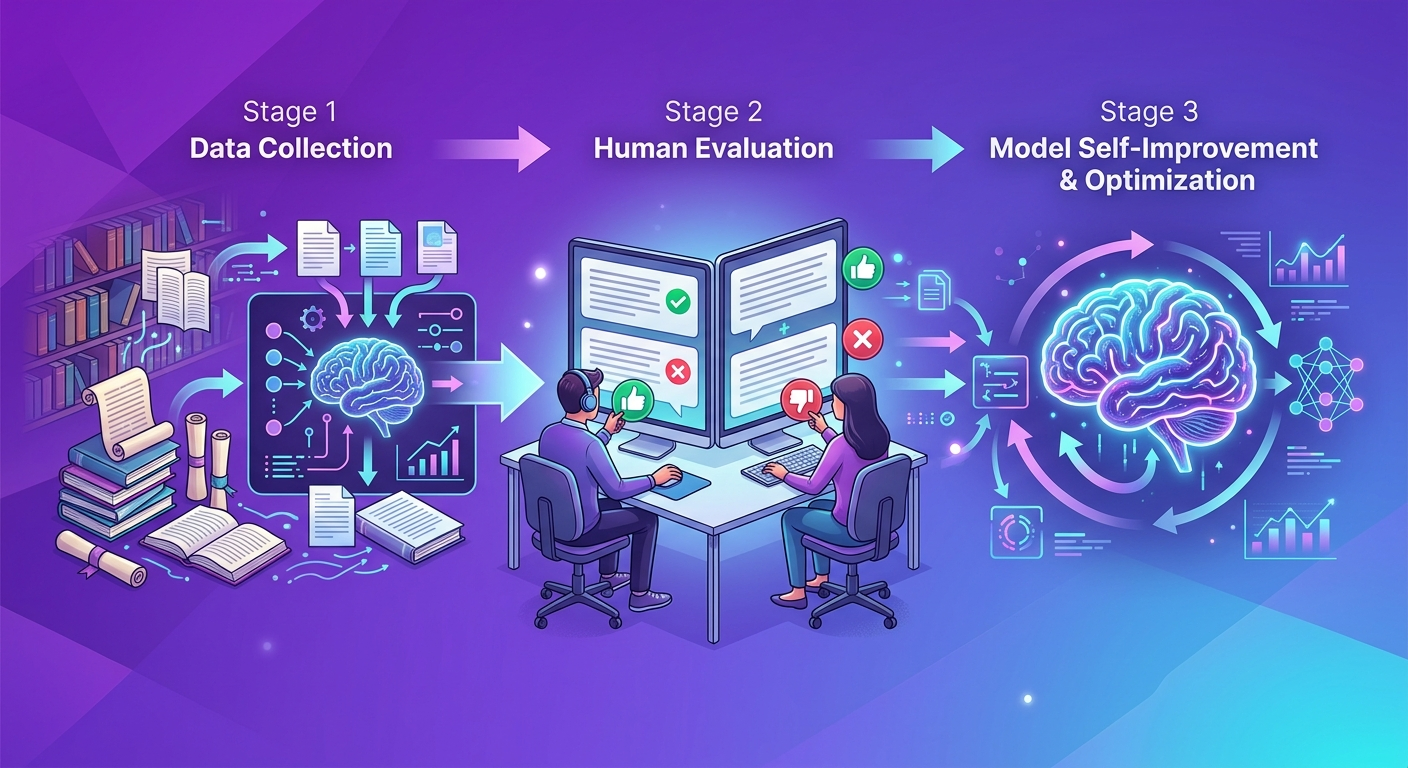
Uczenie przez wzmacnianie nie jest abstrakcyjną teorią. Używasz go codziennie, często nie zdając sobie sprawy.
Gdy klikasz "thumbs up" albo "thumbs down" pod odpowiedzią ChatGPT, wysyłasz sygnał zwrotny. OpenAI zbiera te dane i używa ich do dalszego treningu. Model uczy się, które odpowiedzi ludzie cenią.
Dlatego GPT-5 jest lepszy od GPT-4 nie tylko w benchmarkach - jest lepszy w rozumieniu intencji. Wie, że gdy pytasz "jak to zrobić", chcesz kroków, nie historii.
Algorytm rekomendacji to klasyczne RL. Agent (algorytm) proponuje film. Środowisko (Ty) reaguje: oglądasz do końca (nagroda) albo wyłączasz po 30 sekundach (kara). Algorytm dostosowuje strategię.
Po roku YouTube wie, że lubisz dokumenty o kosmosie, ale nie zniesiesz clickbaitowych tytułów. Zbiera sygnały i optymalizuje.
DeepMind (Google) użył RL, żeby nauczyć AI grać w Go i pokonać mistrza świata. Agent grał miliony partii sam ze sobą, uczył się strategii przez nagrody (wygrana) i kary (przegrana).
Podobnie roboty przemysłowe uczą się chwytać przedmioty. Próbują, upuszczają (kara), próbują inaczej, w końcu chwytają (nagroda). Po tysiącach prób są precyzyjne.
Jeśli chcesz zrozumieć RL głębiej (albo nawet spróbować trenować prosty model), oto co warto wiedzieć:
Jeśli chcesz pobawić się RL bez wchodzenia w głęboką matematykę:
Jeśli Twoim celem jest używanie AI (np. wdrożenie chatbota), nie musisz rozumieć RL od strony implementacji. Wystarczy, że wiesz, jak to działa koncepcyjnie - żebyś wiedział, dlaczego model czasem popełnia błędy i jak go poprawić (przez feedback).
Nie. Deep learning to technika budowy sieci neuronowych (warstwy neuronów przetwarzające dane). Uczenie przez wzmacnianie to sposób trenowania modelu - przez nagrody i kary. Możesz używać deep learning w RL (np. sieć neuronowa jako agent), ale to dwa różne pojęcia. Deep learning odpowiada na "jak model przetwarza dane", RL odpowiada na "jak model się uczy, co jest dobre".
RL optymalizuje model na podstawie średnich ocen ludzkich. Jeśli 80% ludzi uznało odpowiedź A za lepszą niż B, model nauczy się preferować A. Ty możesz być w tych 20%, którzy wolą B. Dodatkowo model nie ma dostępu do najnowszych danych (cutoff wiedzy) i czasem "halucynuje" - generuje coś, co brzmi dobrze, ale jest fałszywe. RL redukuje ten problem, ale go nie eliminuje.
Zależy, co chcesz osiągnąć. Trenowanie dużego modelu językowego od zera (jak GPT-5) kosztuje miliony dolarów i wymaga setek GPU. Możesz wytrenować prosty model RL do gry w Pong albo sterowania symulowanym robotem na swoim laptopie w kilka godzin. Albo użyć fine-tuningu - wziąć gotowy model (np. Llama 4 Scout, open-source) i dotrenować go na swoich danych. To kosztuje setki dolarów, nie miliony.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Uczenie przez wzmacnianie to mechanizm, który sprawia, że AI nie tylko generuje tekst, ale generuje tekst pomocny. Działa przez próby, błędy i sygnały zwrotne - dokładnie jak Ty, gdy uczyłeś się czegoś nowego.
Nie musisz rozumieć matematyki, żeby korzystać z GPT-5 czy Claude Opus 4.7. Wiedza, że model został wytrenowany przez miliony ocen ludzkich, pomaga zrozumieć jego mocne strony (dostosowanie do kontekstu) i słabości (czasem preferuje odpowiedzi popularne, nie najlepsze dla Ciebie).
Jeśli chcesz eksperymentować - zacznij od OpenAI Gym i prostych symulacji. Jeśli chcesz tylko używać AI skutecznie - wystarczy, że wiesz, jak dawać feedback (thumbs up/down w ChatGPT) i jak formułować pytania, żeby model rozumiał intencję.
Następnym razem, gdy użyjesz ChatGPT, Claude albo innego asystenta AI, kliknij thumbs up albo thumbs down pod odpowiedzią. To prosty gest, ale właśnie tak trenuje się modele - Twój głos liczy się w milionach sygnałów, które kształtują przyszłe wersje AI.
Na podstawie: materiałów kursu AI Evolution
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Teoria uczenia maszynowego To przypomina matematyczny koszmar? Ten przewodnik rozbija założenia, bias-variance tradeoff i VC dimension na zrozumiałe kroki - bez doktoratu.

Context Engineering to sposób na lepsze wyniki z AI. Dowiedz się, jak dostarczać modelom właściwy kontekst, by otrzymać dokładne odpowiedzi - bez żargonu i zaawansowanej wiedzy technicznej.

Chcesz zrozumieć, jak naprawdę działają duże modele językowe? Zbuduj swój własny - krok po kroku, bez magii. Przewodnik dla osób bez doświadczenia w programowaniu.

Prompt engineering to nie magia, tylko umiejętność zadawania właściwych pytań. Poznaj konkretne techniki, które sprawią, że ChatGPT zacznie dawać Ci użyteczne odpowiedzi.

Regresja liniowa dobrze sprawdza się na prostych danych. Ale co zrobić, gdy zależności nie układają się w linię prostą? Poznaj dwa rozszerzenia: regresję lokalnie ważoną i logistyczną.

Bias i variance to fundamenty uczenia maszynowego. Zrozumiesz je w 10 minut - ale opanowanie zajmie lata. Zacznij od podstaw, które działają.
